The phrase "conversational analytics" is showing up in more product descriptions every quarter. Some of those products translate questions into live queries against real data. Others bolt a chatbot onto a pre-built dashboard and call it the same thing. The difference between those two architectures determines whether you are buying a new capability or a new interface on an old one.
If you are evaluating tools in this category—whether for an agency managing client accounts or an in-house team tired of waiting on analysts—the criteria that matter are not the ones most comparison pages highlight. This guide covers what to test, what to ask, and what to walk away from.
The architectural test: query generation vs chat layer
The single most important distinction in this category is whether the platform generates a new query for every question or whether it searches pre-computed answers.
A conversational analytics platform takes your natural-language question, translates it into a data query (SQL, an API call, or both), executes that query against your connected sources, and interprets the results into a written explanation. Every question produces a fresh answer grounded in current data. You can ask questions the product designers never anticipated, because the system is not limited to what was pre-built.
A chat layer on a dashboard does something different. It takes your question, maps it to an existing chart or metric tile, and surfaces what is already rendered. The answers are constrained to what the dashboard was configured to show. Ask something outside that scope and you get a generic fallback or no answer at all.
The test is simple: ask the platform a question that no one on the vendor's team anticipated. Something specific to your business, your date range, your campaign structure. If it answers with real numbers grounded in your data, it is generating queries. If it redirects you to a pre-built view or gives a vague response, it is a chat layer.
Data connectivity: what "connects to your data" actually means
Every platform in this space claims to connect to Google Ads, Meta, GA4, and the rest. The useful question is not which platforms are listed on the integrations page—it is how the data flows after connection.
Direct API queries vs synced snapshots. Some tools query your marketing platforms live at the moment you ask a question. Others sync data on a schedule—hourly, daily, or on-demand—into a normalised store. Both approaches have tradeoffs. Live queries guarantee freshness but depend on API rate limits and response times. Synced data enables faster answers and cross-platform joins but introduces a lag between reality and what the platform knows.
The best implementations do both: maintain a synced data layer for fast, complex queries while falling back to live API calls when freshness matters. Ask the vendor which approach they use and when each path triggers.
Cross-platform joins. If you ask "how does paid traffic from Google Ads compare to organic traffic from Search Console this month?"—does the platform answer in a single response, or does it require two separate questions? True cross-platform capability requires a normalised data model where metrics from different sources share a common schema. This is non-trivial engineering. Many tools that list multiple integrations still answer them in isolation.
Data availability after connection. How far back does data go after you connect a source? Is historical data backfilled, or does the platform only know about data from the connection date forward? For agencies onboarding new clients, this determines whether you can answer questions about last quarter on day one.
Query flexibility: can you ask anything or just what was anticipated
This is where most evaluations go wrong. Demos show impressive answers to prepared questions. The real test is what happens with unprepared ones.
Open-ended questions. Type "why did CPA increase last week?" and see whether the platform identifies the specific campaigns, ad groups, or audience segments driving the change—or whether it returns a top-level number with no breakdown.
Compound questions. Ask something that requires comparing two time periods, two channels, or two clients. "How did our Google Ads CPA compare to Meta CPA in the last 30 days vs the prior 30 days?" This requires joining data across sources and time ranges in a single answer. Many tools cannot do this.
Follow-up questions. After getting an answer, ask a follow-up that builds on it. "Which campaigns drove that increase?" or "What was the daily trend?" A platform with real conversational capability maintains context across the thread — the Ask interface should feel like a conversation, not a search bar. One without it treats every question as independent.
Edge cases. Ask about a metric that exists in your data but is not a standard KPI. Search impression share in Google Ads. Scroll depth in GA4. Average position in Search Console. If the platform only handles the top ten metrics, it will fail on the long tail of questions your team actually needs answered.
Output quality: explanations vs numbers
The output of a conversational analytics platform should be an explanation, not a data table. This is what separates the category from dashboards—the answer should be something a non-analyst can read, understand, and act on without further interpretation.
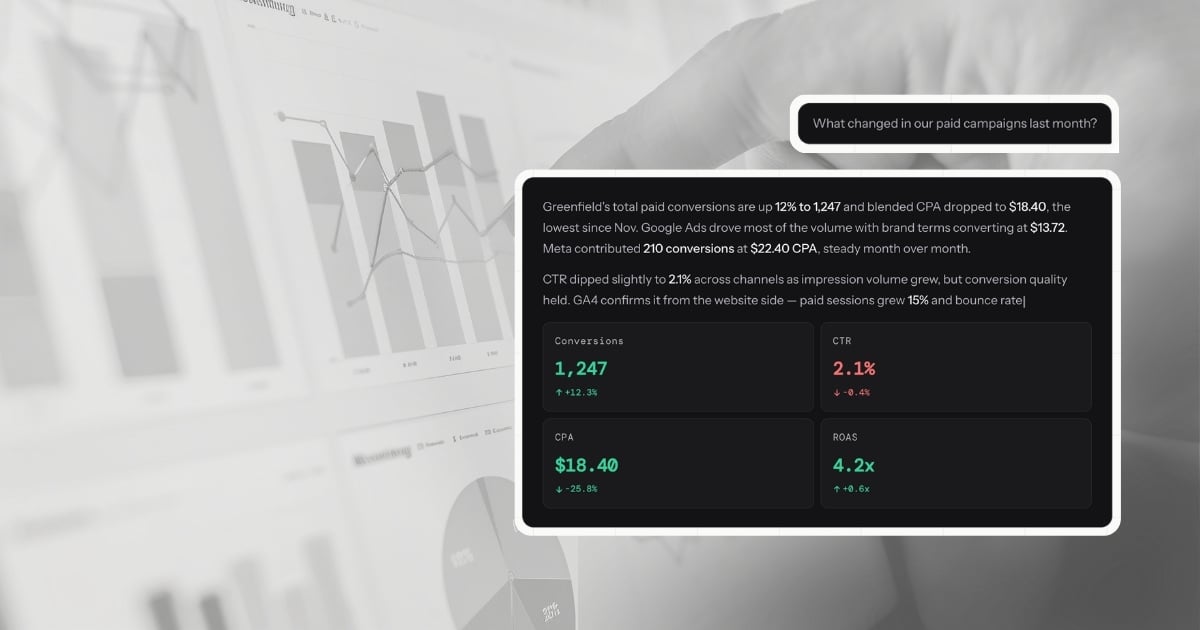
Specificity. Does the answer say "revenue declined 12% to $34,200, driven by a 28% drop in Meta remarketing conversions" or does it say "revenue declined significantly"? The first is useful. The second is noise.
Causal reasoning. Does the platform attempt to identify why something changed, or does it just report what changed? A good answer traces a metric movement to a specific driver—a campaign pause, an audience change, a seasonal pattern. A weak answer restates the number in sentence form.
Comparison anchors. Every meaningful metric needs context. Is a $42 CPA good or bad? Compared to last week, last month, or the account average? The answer should include at least one comparison anchor without you having to ask for it.
Actionable next steps. The best answers end with a clear implication: "Consider pausing Campaign X" or "This trend suggests reallocating budget from Brand to Non-Brand." Not every answer warrants a recommendation, but the platform should surface one when the data supports it.
Client-readiness. For agencies, the ultimate test is whether you could send the answer to a client as-is—no editing, no reformatting, no adding context. If every answer requires 10 minutes of cleanup before it is presentable, the tool is saving you query time but not communication time, and communication time is the real bottleneck.
Accuracy and trust: the hardest thing to evaluate in a demo
Accuracy is the criterion everyone claims and almost no one tests rigorously during evaluation. An inaccurate answer that reads well is worse than no answer at all—it erodes trust with the one audience you cannot afford to mislead: your clients.
Cross-reference against source. Pick three answers from the platform and verify them against the raw data in Google Ads, GA4, or whatever source was queried. Check the specific numbers, the date ranges, and the comparisons. Discrepancies of more than 1-2% on core metrics like spend or conversions indicate a data pipeline problem.
Ask the same question twice. Deterministic queries should return the same answer. If you ask "what was our Google Ads spend last week?" on Monday and again on Wednesday (with no new data synced in between), the answer should be identical. Variation suggests the query generation is inconsistent.
Test with known scenarios. If you know that a particular campaign was paused on March 5th, ask "why did conversions drop in the second week of March?" and see whether the platform identifies the pause. This tests whether the system connects cause and effect or just reports the symptom.
Ask about data that does not exist. Ask about a platform you have not connected or a date range before your data begins. A trustworthy platform should tell you it does not have the data rather than fabricating an answer. Hallucination—confident answers with no data behind them—is the most dangerous failure mode in this category.
Speed: the threshold that matters
If an answer takes more than five seconds, something in the architecture is wrong. Users will tolerate a brief pause for a complex cross-platform analysis, but routine questions—"what was our spend last week?"—should resolve in two to three seconds.
Test latency across three scenarios: a simple single-metric question, a comparison across two time periods, and a cross-platform question. If any of these consistently exceeds five seconds, ask the vendor what is causing the delay. Common culprits are unoptimised query generation, lack of caching, or slow API calls to upstream platforms.
Streaming matters here. A platform that starts showing the answer as it generates—sentence by sentence—feels faster than one that shows a spinner for four seconds and then renders the full response. This is not a gimmick. It is a meaningful UX difference when you are asking dozens of questions in a session.
Red flags in demos and trials
Watch for these during your evaluation. Each one signals a deeper architectural or quality problem.
Canned questions only. If the demo only shows pre-selected questions and the presenter avoids typing a custom one, the query flexibility is limited. Ask to type your own question during the demo.
No source attribution. Every answer should tell you where the data came from—which platform, which date range, how fresh the data is. If the answer appears with no provenance, you cannot verify it, and neither can your client.
"Coming soon" on core features. Cross-platform queries, follow-up context, and export to PDF are not nice-to-haves. They are baseline capabilities. If these are on a roadmap rather than in the product, you are evaluating a pitch, not a platform.
Dashboard-first architecture. If the product's primary interface is still a dashboard builder and the conversational feature feels bolted on—a sidebar chat, a search bar that filters existing widgets—the conversation is not the product. It is a feature. The distinction matters because a feature will always be constrained by the architecture it was added to. The same applies to general-purpose AI tools like ChatGPT—they can discuss marketing concepts but lack the data connectivity and query pipeline to answer questions about your actual accounts.
No error handling for bad questions. Ask a vague or unanswerable question. A mature platform responds with a clarifying question or a clear statement of what it cannot answer. An immature one returns a confidently wrong answer or a generic error.
Questions most buyers forget to ask
These rarely appear on feature comparison sheets, but they determine whether the product works in practice.
How does accuracy degrade with complex questions? Simple lookups are easy. Multi-step reasoning—"which campaign had the biggest CPA improvement after we changed the bidding strategy last Tuesday?"—is where accuracy falls apart. Ask the vendor what their accuracy looks like on compound, multi-step questions versus simple metric lookups.
What happens when I hit the query limit? Every platform has usage tiers. Find out what happens at the boundary. Does the platform stop answering entirely, degrade to cached results, or throttle response speed? The answer shapes your team's experience at the end of a busy month.
Can the output go directly to a client? Not "can I export it" but "is the explanation written at a level where a marketing director at my client's company would understand it without calling me to ask what it means?" Test this by showing a real answer to someone outside your analytics team.
How does the platform handle data it has never seen? Connect a new data source and ask a question immediately. The pipeline that translates questions into queries must understand the schema of whatever data it encounters—not just the schemas it was trained on during development. For the full technical breakdown of how this pipeline works inside LDOO, see how conversational analytics works under the hood. This separates general-purpose engines from hardcoded integrations.
What is the caching strategy? Caching affects both speed and cost. Understand whether repeated questions hit the cache (faster, cheaper) or generate fresh queries every time. A good caching strategy serves cached results instantly while revalidating in the background, so you get speed without staleness.
Who sees my data? Confirm that your marketing data is not used to train models, is not accessible to other customers, and is isolated at the infrastructure level. Multi-tenant architectures should enforce row-level security, not just application-level filtering.
Building your evaluation scorecard
Score each platform across these six dimensions on a 1-5 scale. Weight them according to your priorities, but do not skip any.
Data connectivity (weight: high). Number of supported platforms, normalisation quality, cross-platform joins, historical backfill depth, data freshness.
Query flexibility (weight: high). Open-ended questions, compound queries, follow-up context, long-tail metric support.
Output quality (weight: high). Specificity, causal reasoning, comparison anchors, actionable recommendations, client-readiness.
Accuracy (weight: critical). Cross-referenced numbers, deterministic consistency, known-scenario identification, hallucination resistance.
Speed (weight: medium). Simple query latency, complex query latency, streaming support.
Operations (weight: medium). Export options (PDF, link, scheduled delivery), team collaboration, white-labeling, pricing transparency, usage limits.
A platform that scores 5 on operations but 2 on accuracy is not a good product. Prioritise the first four dimensions. The last two matter, but only after the core capability is proven.
To make this concrete, here is what a 5 versus a 2 looks like on accuracy—the dimension that matters most and is hardest to evaluate in a demo.
Accuracy score of 5: You ask "why did CPA increase for Brand Search last week?" The platform identifies that CPA rose 22% from $31.40 to $38.30, traces the cause to a negative keyword list change on Tuesday that broadened match types, notes that impressions increased 35% while conversions stayed flat, and recommends reverting the keyword list. You verify against Google Ads—the numbers match within 1%.
Accuracy score of 2: You ask the same question. The platform returns "CPA increased last week across your campaigns. This may be due to changes in competition or audience behavior. Consider reviewing your bidding strategy." The number is missing. The cause is speculative. The recommendation is generic. You cannot send this to a client.
The gap between these two outputs is not a UX difference. It is an architectural one. The first requires a system that can identify specific changes, correlate them with metric movements, and cite the evidence. The second is a language model pattern-matching on the word "CPA" without querying the underlying data with enough precision.
The ten-question test
The most reliable evaluation method uses your own data and your own questions. Connect a real client account and ask these ten questions. Score each answer: pass (could send to client as-is) or fail (needs editing, contains errors, or is too vague to be useful).
- What was our total spend last month across all campaigns?
- Why did CPA change last week compared to the week before?
- Which campaign has the highest ROAS over the last 30 days?
- How does our Google Ads performance compare to Meta this month?
- What happened to conversions on [specific date you know something changed]?
- Which ad groups are spending the most with the lowest conversion rate?
- How is our Search Console click-through rate trending over the past 90 days?
- What is our average cost per click by campaign type?
- Compare last month's performance to the same month last year (if data exists).
- Show me the daily spend trend for [specific campaign name] this month.
Seven or more passes means the platform is ready for your workflow. Five or six means it works for simple questions but will fail your team on the investigative ones—the questions that matter most. Fewer than five, and the tool is not ready, regardless of what the feature list says.
The gap between marketing data and client communication is the most expensive workflow in agency operations. The right conversational analytics platform closes it in seconds. The wrong one adds a new interface to the same manual process. For a full overview of how LDOO approaches this as a product, see What is LDOO.
If you want to see what this looks like for client reporting specifically, read what conversational analytics means for client reporting. For a deeper look at how agencies are applying it day-to-day, see conversational analytics for marketing agencies.
How the current tools compare
Eight tools show up most often when agencies search for conversational analytics software. They fall into three categories: general-purpose AI, enterprise BI with natural language, and purpose-built marketing platforms.
| Tool | Type | Live marketing connectors | Client scoping | Client-ready output | Entry price |
|---|---|---|---|---|---|
| LDOO | Purpose-built for agencies | GA4, Ads, Meta, GSC, Shopify, YouTube | Multi-tenant, per-client | Reports, portals, scheduled delivery | $99/mo annual |
| ChatGPT | General-purpose AI | No (file uploads only) | No | No | $20/mo |
| Claude | General-purpose AI | No (file uploads only) | No | No | $20/mo |
| Gemini | General-purpose AI | Google Workspace only | No | No | $20/mo |
| Perplexity | AI research tool | No (web search only) | No | No | $20/mo |
| BlazeSQL | NL-to-SQL for databases | SQL databases only | Per-database | Basic charts | $99/mo |
| Lumenore | Enterprise BI | 100+ via API | Enterprise RBAC | Dashboards, reports | $510/yr |
| Knowi | Enterprise BI | SQL, APIs, NoSQL | Enterprise RBAC | Dashboards | Custom |
The general-purpose AI tools — ChatGPT, Claude, Gemini, Perplexity — can discuss marketing strategy and explain concepts fluently. But none of them connect to your live data sources. Every question about actual performance requires exporting a CSV, uploading it, and hoping the model interprets the columns correctly. These tools predict plausible text based on patterns. They do not execute calculations against real databases. That distinction matters when the number in your client report needs to be verifiably correct, not statistically plausible.
Enterprise tools like BlazeSQL, Lumenore, and Knowi solve the data connection problem. They query real databases and return real numbers. But they are built for data teams, not marketing agencies. Setup requires technical configuration — schema mapping, database credentials, access control policies. None of them understand marketing-specific schemas out of the box (campaign hierarchy, attribution models, platform-specific metrics like GA4 engagement rate or Google Ads quality score). And none support the multi-tenant, per-client scoping that agencies need when managing 15 or 20 accounts from a single workspace.
LDOO occupies the gap between these two categories. It connects to marketing platforms directly via OAuth — no CSV exports, no database credentials, no schema mapping. Data is scoped per client automatically through multi-tenant architecture, so asking "How did Greenfield Digital perform last week?" pulls only Greenfield Digital's data. The output is client-ready by default: branded reports, live client portals, and scheduled email delivery. That end-to-end pipeline — from question to client-facing deliverable — does not exist in any other tool in this list.
Why general-purpose AI is not conversational analytics
ChatGPT, Claude, Gemini, and Perplexity appear in nearly every "conversational analytics" comparison. They should not. These are language models — they generate text that sounds correct by predicting the most probable next token. They do not connect to data sources, execute SQL queries, or verify calculations against real numbers. When you ask ChatGPT "What was my CPA last week?", it does not know. It will either tell you it cannot access your data or, worse, produce a confident answer based on patterns in its training data. Neither outcome is useful for a client report.
The workaround most agencies try is uploading a CSV export. This introduces three problems. First, the data is stale the moment you export it — you are analyzing a snapshot, not your live account. Second, the model may misinterpret column names, date formats, or metric definitions (GA4's "sessions" and Universal Analytics' "sessions" are not the same metric, but a language model treats them identically). Third, there is no audit trail. You cannot trace a number in the AI's answer back to a specific query against a specific data source at a specific time. If a client questions a figure, you have nothing to point to.
Some platforms have tried to bridge this gap by adding a data layer on top of general-purpose AI — uploading structured data into an AI context window, then letting the model reason over it. The core problem persists. The AI is still predicting text, not executing verified calculations. Adding a middleware layer between the AI and the data does not change the fundamental architecture: the model generates an answer that looks right rather than computing one that is right. The fix is not bolting data access onto a language model. It is starting with a query execution engine and using AI for interpretation after the numbers are already verified.
True conversational analytics means a verified pipeline: natural language in, structured query executed against live data, results interpreted with source attribution and audit trail. The user asks a question. The system generates a query, runs it, and returns numbers it can prove. The AI layer explains those numbers — it does not produce them. That architecture is what separates a conversational analytics platform from a chatbot with a spreadsheet attached.