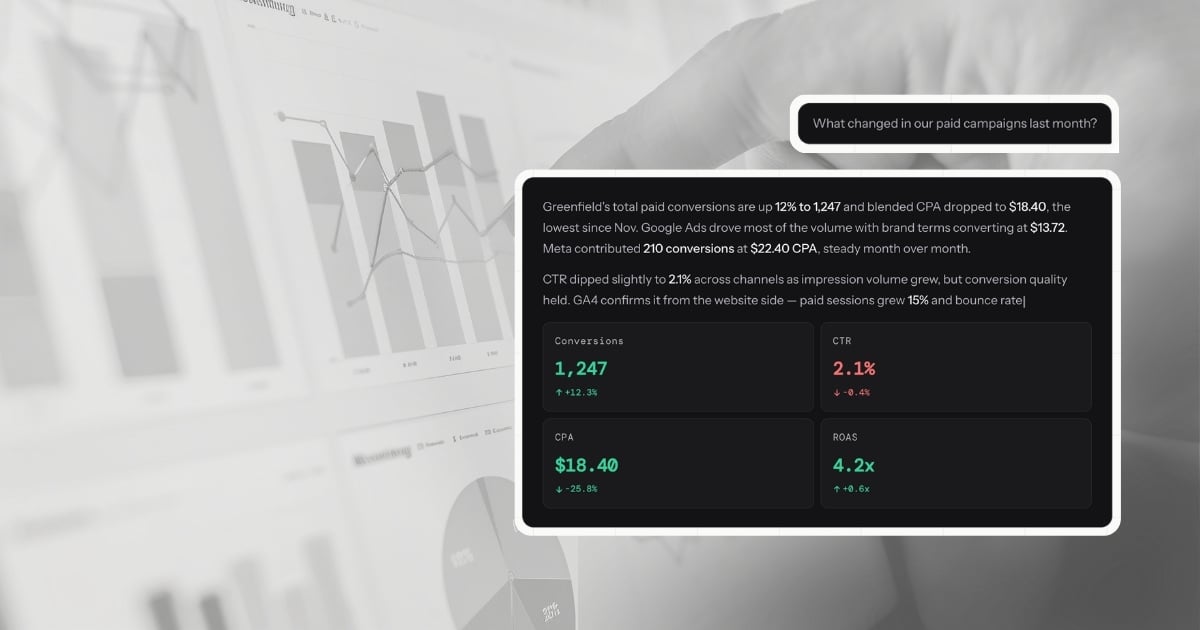
Every time you type a question into LDOO - "What happened to our Google Ads CPA last week?" - the answer appears in a few seconds. It includes specific numbers, a comparison to the previous period, a likely cause, and a suggested next step. It reads like a senior analyst wrote it.
But there is no analyst. There is a pipeline of connected systems, AI models, validation checks, and safety rails that turns your plain-English question into a grounded, data-backed explanation. This post walks through exactly how that works - every layer, from the moment your data connects to the moment the answer hits your screen.
Step zero: connecting your data
Before LDOO can answer anything, it needs access to your marketing platforms. You connect each source through a standard OAuth flow - the same secure handshake you use when you log into an app with your Google account. LDOO never sees or stores your platform passwords. Instead, it receives a token - a limited-permission key that lets it read your data and nothing else.
LDOO connects to major marketing platforms including Google Analytics (GA4), Google Ads, Meta Ads, Search Console, Shopify, YouTube Analytics, Google Sheets, Microsoft Clarity, and LinkedIn Ads - with more being added. Each connection takes about 30 seconds. You select the property or account you want to connect, authorize the access, and LDOO begins syncing.
What happens during a sync
When you connect a data source, LDOO runs a background sync job that pulls your marketing data and normalises it into a unified format. Every platform reports data differently - Google Ads measures clicks and conversions per campaign, GA4 tracks sessions and pageviews per page, Search Console counts impressions and clicks per search query. LDOO maps all of this into a single, consistent schema.
That schema stores every row with the same core fields: the source (which platform), the entity type (campaign, ad group, keyword, page, product), the date, and a standard set of metrics - impressions, clicks, conversions, spend, revenue, CTR, CPC, CPA, and ROAS. Platform-specific fields that do not fit this structure are preserved in an extensible metadata column, so nothing is lost.
This normalisation step is critical. It means LDOO can answer cross-platform questions - "How does paid vs organic traffic compare this month?" - without you needing to think about which data lives where.
After the sync completes, a finalisation step updates the connection status, clears any stale cached answers, and triggers an anomaly scan (more on that later). The whole process runs in the background using a job queue, so it never blocks anything you are doing in the app.
Keeping tokens fresh
OAuth tokens expire. Google tokens last about an hour. LDOO handles this transparently - when it needs to query a platform and the token is close to expiring, it automatically refreshes the token before making the request. If the refresh fails (because you revoked access or the token was invalidated), the connection is marked as expired and LDOO prompts you to reconnect. All tokens are encrypted at rest using AES-256 encryption.
The question pipeline: from English to answer
When you ask LDOO a question, it does not go to a single AI model that magically produces an answer. It passes through a five-step pipeline, where each step has a specific job and its own quality checks. Think of it as an assembly line for intelligence.
Here is the full sequence:
- Plan - Understand what you are asking and build a data retrieval strategy
- Fetch - Get the data, either live from the platform APIs or from the synced database
- Interpret - Turn the raw data into a natural-language explanation
- Verify - Score the explanation against a quality checklist
- Enrich - Add charts, tables, confidence indicators, and follow-up questions
Each step is a separate module. If any step fails, the pipeline has fallback paths so you still get an answer - it might note that one data source was unavailable or that the answer is based on cached data, but it does not leave you with nothing.
Step 1: Understanding your question
The first AI model reads your question and produces a structured query plan. This is not a SQL query yet - it is a formal description of what data is needed to answer the question.
For example, if you ask "Which campaigns had the highest CPA last month?", the planner produces a plan that says: I need CPA and spend metrics, grouped by campaign name, filtered to last month's date range, sorted by CPA descending, limited to the top 10.
This step uses Anthropic's Claude in a deterministic mode - meaning it produces repeatable output. The same question with the same context will always produce the same plan. The model receives the full schema of available data (what columns exist, what they mean, example values), the list of connected integrations, the date range of available data, and any conversation context from earlier questions in the thread.
The planner does not guess. If your question is ambiguous - "How are things going?" - it maps it to a reasonable default (a performance overview of your main metrics) and flags the ambiguity so the interpretation step can acknowledge it. If you ask about a platform that is not connected, the plan notes this and suggests the closest available alternative.
Query plans are cached. If you or a teammate asks the same question shortly after, the plan is reused, saving time and cost.
Step 2: Getting the data
With a plan in hand, LDOO fetches the data. This is where it gets interesting, because LDOO uses a dual-source architecture: it can query your marketing platforms directly via their APIs (live data) or read from its own synced database (stored data). It prefers live data when available.
Live queries go directly to the platform. For Google Analytics, this means calling the GA4 Data API. For Google Ads, it uses the Google Ads Query Language. For Search Console, the Search Analytics API. For Meta, the Marketing API. Each API has different authentication, rate limits, query formats, and response structures. LDOO handles all of this internally.
If a platform is slow or rate-limited, LDOO does not wait indefinitely - it falls back to the synced database and notes that the data may be slightly older. If multiple sources are needed (say, Google Ads and GA4 for a cross-platform question), they run in parallel.
Database queries use the normalised data from your last sync. These are fast and reliable, but the data is only as fresh as the last sync. LDOO tracks the age of each data source and displays a freshness indicator on every answer - "Live data" with a green dot, "Cached - 3h ago" in grey, or "Mixed" in amber when some sources are live and others are cached.
There is also a smart caching layer. If you ask a question that was recently answered, LDOO serves the cached answer immediately while re-running the pipeline with live data in the background. If the new data is different, the answer updates in place. If the data has not changed, it just updates the freshness indicator. This means repeat questions feel instant without sacrificing accuracy.
Step 3: Interpreting the results
This is the most important step - and the one that uses the most capable AI model in the pipeline.
The interpretation step receives the raw data (rows of metrics and dimensions), the original question, the query plan, and a rich context window that includes:
- The conversation thread so far (so follow-up questions make sense)
- 90-day statistical baselines per metric per client — so the model knows what "normal" looks like and can say "CPA is 18% above the 90-day norm" rather than just "CPA increased 18%"
- Dimensional investigation results — when a metric moves significantly (significance score above 50), the pipeline automatically runs a breakdown by campaign, device, region, and channel before the interpret step, so the model receives the root cause analysis, not just the top-line change
- Client goals and context — industry, primary KPI, KPI targets, and seasonality notes shape how the model frames performance
- Key findings from your previous conversations about this client (up to 30 days back)
- Any active anomaly alerts for this client — and if a critical alert scores highly against the current question, the answer opens with it
- Recent report narratives (so the AI can reference "as noted in your last report")
- Client memories — distilled facts from past reports and corrections (e.g. "this client considers ROAS below 3x unacceptable" or "Q4 is always noisy for this account")
- Recent negative feedback (so it avoids repeating mistakes you flagged)
All of this context is budget-controlled - each layer has a character limit so the most relevant information always fits without overwhelming the model with noise.
The interpretation step uses Anthropic's most capable Claude model. Phrasing varies naturally so answers do not read identically every time, while the substance remains grounded in your data. The response streams back to your screen in real time, so you see the answer being written as the model generates it.
The output is not just text. It is a structured payload that includes:
- The written explanation (what happened and why)
- Metric cards (the key numbers, with period-over-period comparisons and trend arrows)
- Source attribution (which platforms the data came from)
- Follow-up questions (3-5 natural next questions you might want to ask)
- Confidence level (how reliable the answer is, based on data volume and freshness)
- Data freshness metadata (which sources are live vs cached, and how old the data is)
Step 4: Checking the answer
Before the answer reaches you, it passes through a verification step. A separate, fast AI model scores the answer against a quality checklist:
- Specific numbers - Does the answer contain concrete metrics, not vague claims?
- Primary cause - If the question is diagnostic ("why did CPA spike?"), does the answer state a direct cause?
- Supporting observation - Is there a second data point that validates the primary finding?
- Comparison anchor - Does it compare against the previous period, a benchmark, or a target?
- Actionable implication - Does it suggest what to do next, even briefly?
The answer must pass a majority of these checks. If it fails, the pipeline retries the interpretation with feedback about what was missing. This verification step is the reason LDOO answers read like analyst briefings rather than chatbot responses.
For certain question types - like a simple portal layout or a quick metric lookup where the numbers speak for themselves - the verification step is skipped to avoid unnecessary latency.
Step 5: Enriching the answer
The final step adds the visual and structural elements that make the answer useful beyond the text:
- Metric tiles with the headline numbers, period-over-period change percentages, and semantic colour coding (green for improvements, red for declines - with smart inversion for metrics like CPA where down is good)
- Charts selected automatically based on the data shape (line charts for trends, bar charts for comparisons, horizontal bars for rankings)
- Data tables for detailed breakdowns (campaign-level performance, keyword rankings, page-level metrics)
- Confidence indicators that flag when the data is based on a small sample, a narrow date range, or stale sync data
- Sparklines showing daily trends for the key metrics
The enriched answer is then cached for fast retrieval on repeat questions. The conversation message is saved to the database, and usage is tracked for billing.
The models and why we use three of them
LDOO uses three different AI models, each chosen for a specific job:
The planner handles query planning. It is fast, deterministic, and structured. Planning is a mechanical task - translating a question into a data retrieval strategy. It does not need the narrative sophistication of a larger model.
The interpreter handles the explanation. This is the step where quality matters most. The explanation needs to be specific, causal, contextual, and actionable. This is Anthropic's most capable Claude model - because the interpretation step is the one your clients will read, and we do not cut corners here.
The verifier handles quality checks and plan repair. These are fast, mechanical tasks - scoring an answer against a rubric, or catching issues before they reach you. The fastest model in the family, chosen for speed rather than depth.
This tiered approach ensures the highest quality where it matters most (the explanation your clients read) while keeping the overall pipeline fast and efficient.
The guardrails that keep answers accurate
Accuracy is not optional. An agency sending LDOO answers to clients cannot afford a wrong number or a hallucinated cause. Here are the guardrails built into every answer:
Data scoping
Every query is scoped to your account and your client. This is enforced at two levels: the application layer (the SQL compiler always injects account and client filters) and the database layer (PostgreSQL Row Level Security policies prevent any query from accessing another account's data, even if the application layer had a bug). This is defense in depth - a standard security practice where multiple independent layers enforce the same constraint.
Source enforcement
If you ask "What is our Google Ads CPA?", the answer must come from Google Ads data - not GA4, not Meta. The pipeline enforces this with a server-side safety net that detects when a question names a specific platform and overrides the query plan if the AI planner missed it. This prevents a common failure mode where the AI uses the wrong data source and produces a technically valid but factually wrong answer.
Fuzzy matching for entity names
When you ask about a specific campaign - "How is the Brand Search NZ campaign doing?" - the pipeline fuzzy-matches the name against actual campaign names in your data. If there is no exact match but a close one exists ("Brand Search - NZ"), it uses the closest match and tells you it made a correction. This prevents zero-result answers caused by minor naming differences.
Confidence assessment
Not all data is equally reliable. An answer based on 5 clicks over 2 days is less trustworthy than one based on 5,000 clicks over 30 days. LDOO evaluates the sample size, date range coverage, and data freshness of every answer. If the data is thin, the answer includes a confidence badge explaining why ("Based on only 8 clicks - too small for reliable trends").
Feedback loop
When you give an answer a thumbs down, LDOO stores the feedback and the question type. Recent negative feedback is injected into the interpretation prompt as quality notes, so the AI actively avoids repeating the same mistake. This creates a self-improving system - the more you use it, the better it gets at answering your specific types of questions.
Billing-enforced rate limits
Every question is tracked against your plan's monthly limit. The limit check is atomic - it verifies the quota and increments the counter in a single database operation, preventing concurrent requests from both passing the limit. This is a billing guardrail, but it also prevents runaway API costs if something goes wrong.
The evaluation system
We do not ship prompt changes or pipeline updates without testing them against a standardised set of questions. LDOO maintains a growing library of golden query fixtures - real questions with known-correct answers, covering every question type (overview, trend, comparison, ranking, breakdown, diagnosis) across every connected platform.
Each fixture includes the expected answer structure, the correct trend directions (CPA went up, sessions went down), the semantic colour coding (CPA up should be red, not green), and minimum accuracy and format scores. When we change the pipeline, we run every fixture through it and compare the results. If any fixture regresses, the change does not ship.
The scoring system evaluates answers on two dimensions:
- Accuracy (0-3): Does the answer contain the right numbers, the right cause, and the right context?
- Format (0-3): Is the output structure complete - sources, follow-ups, confidence, freshness?
A score of 3/3 on both dimensions means the answer is client-ready without any editing. That is the bar.
What this means for you
All of this - the pipeline, the models, the guardrails, the evaluation system - exists so that when you ask "What changed this week?", the answer is specific enough to paste into a client email without touching it.
You do not need to understand any of the technology described here to use LDOO. You just type a question. But we think it matters that you know what is happening behind the scenes, because trust in the answer is everything. If you cannot trust the numbers, the explanation, and the recommendation, then conversational analytics is just a gimmick.
We built LDOO so that it is not a gimmick. Every answer is grounded in your actual data, validated against a quality standard, and transparent about its confidence level and data freshness.
Why not just use ChatGPT?
It is a fair question. General-purpose language models like ChatGPT, Claude, and Gemini are remarkably capable at generating text that sounds like data analysis. You can paste a CSV into a chat window and ask "what happened to revenue last month?" and get a confident, well-structured answer. The problem is that the answer might be wrong, and you have no reliable way to know.
When people say they want to talk to their data, they mean something more specific than uploading a CSV to a chatbot. They mean asking a question and getting a verified answer drawn from their actual, current data — not a plausible-sounding prediction assembled from token probabilities. General-purpose LLMs are trained to predict the next likely token in a sequence. When one says "Revenue was $42,300 last month," that number is not the result of a calculation. It is the model's best guess at what a convincing revenue figure looks like in context. This is the hallucination problem, and it is not a bug that will be patched — it is a fundamental property of how autoregressive language models work. They generate plausible text, not verified arithmetic.
The file-upload workflow compounds the issue. Every time you want an answer, you export data from Google Analytics or your ad platform, format it, upload it, and hope the file fits within the model's context window. For a single client with a few weeks of data, this might work. For an agency managing fifteen clients across four platforms with months of historical data, it breaks down immediately. The data is stale the moment you export it. The context window cannot hold the full dataset. And you repeat the entire process next week when the client asks the same question about fresher numbers.
LDOO's pipeline is architecturally different. Your natural-language question is converted into a SQL query plan, validated for safety, and executed against your live, synced data — the same marketing_data table that the sync engine populates every six hours. The AI layer only enters the picture after the query returns verified results. It interprets real numbers; it does not generate them. The SQL is visible, the data sources are attributed, and a verification pass checks the interpretation against the raw results before the answer is delivered. The numbers in the response are the numbers in the database, not a language model's best guess.
There is also the question of what happens after the answer. A general-purpose chatbot gives you text in a chat window. There is no concept of client scoping — you cannot ask "how did Client X perform vs Client Y?" because there is no multi-tenant data model connecting your accounts, clients, and integrations. There is no output pipeline. You cannot generate a branded PDF report from that answer, create a live client portal your client can bookmark, or schedule automated weekly delivery. In LDOO, every answer is a launchpad: the same conversation that produced the explanation can produce a report, a portal, or a recurring delivery — all without leaving the thread. The difference is not a better prompt. It is a different system.